Google’s Open Knowledge Format (OKF) is the first open standard for structuring your company’s knowledge so AI agents can read it. Google Cloud released version 0.1 in June 2026. It is a set of plain markdown files, organized in folders, with a small block of structured text at the top of each file that tells an AI what the file contains.
At TJ Digital, we run AI search optimization for roughly 40 to 50 client websites. A structured knowledge base sits at the center of every campaign. We build one for every client and call it a Brand Ambassador.
OKF is close enough to the best practices we already use that adopting it now is a safe move. My advice is the same one I give every business owner. Start collecting and organizing your company’s knowledge today.
Table of Contents
ToggleWhat Is Google’s Open Knowledge Format?
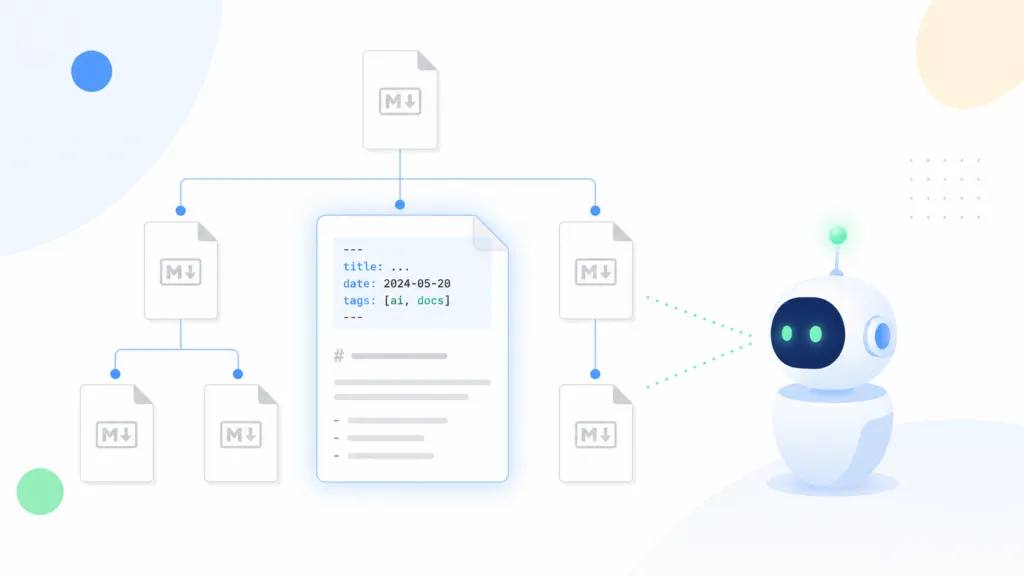
OKF is an open, vendor-neutral specification for storing internal company knowledge as agent-readable documents. Each file represents a single concept, like a metric, a runbook, an API, or a brand policy.
The format is about as simple as it gets. There is no SDK to install and no compression schema to worry about. It is just markdown files in a nested set of folders, with a short header at the top of each one.
I recorded a video the day it dropped, then recorded another one in 100-degree heat because I was that excited about it. The spec itself is simple and sensible. What has me excited is that we finally have a standard at all.
@tjrobertson52 What is Google’s Open Knowledge Format? The first real standard for structuring your company’s knowledge for AI. #AI #AIagents #OKF
♬ original sound – TJ Robertson – TJ Robertson
How Is an OKF Knowledge Base Structured?
An OKF knowledge base is a hierarchy of folders. A top-level folder might be sales, with subfolders like sales/tables underneath it. Each concept lives in its own markdown file, and the file’s path acts as its ID.
Inside any folder you can add an optional index.md file that lists everything in that folder, which lets an agent read the index before drilling into details. You can also add an optional log.md file to track changes over time.
The one piece that matters most is the header at the top of each file. It is written in YAML frontmatter, which is just a few lines of text between two markers. Only one field is required, and the rest are recommended.
| Field | Required? | What it does |
| type | Yes | A short label like “Playbook” or “BigQuery Table” that tells an agent how to handle the file |
| title | Recommended | A human-readable name for the concept |
| description | Recommended | A one-line summary that becomes the preview an agent sees |
| resource | Recommended | A link to the canonical source, such as a database table |
| tags | Recommended | Keywords for categorizing and filtering files |
| timestamp | Recommended | When the file was last updated |
You can add as many custom fields as you want beyond these. Here is what a finished file looks like.
—
type: Playbook
title: Refund Policy
description: How we handle customer refund requests.
tags: [support, policy]
timestamp: 2026-06-01T10:00:00Z
—
# Refund Policy
We refund any order within 30 days of purchase…
If that looks complicated, it is not. It is some text at the top of a file, and then your normal markdown underneath it.
Why Does a Standard for AI Knowledge Matter?
The format itself is simple. Its value comes from everyone agreeing on the same shape.
If we all structure knowledge the same way, every AI agent, prompt, or skill can assume that structure. We move from building custom processes in isolation toward sharing and improving each other’s work. That shift has to happen for AI adoption to keep moving quickly.
Right now most company knowledge sits in fragmented systems, locked inside whatever tool created it. A standard gives those silos a common language so any agent can read across them.
Google also has a track record of getting standards adopted, which is a big reason I think this one will stick. WebMCP is a recent example. There are no real competing standards for this right now, and the format makes sense, so I would not bet against it.
Where Should You Store Your OKF Files?
OKF is platform agnostic, so the files can live anywhere. The goal is to keep each file in a single location that any tool can read.
Most businesses will probably store these in GitHub, and that is what we plan to do ourselves. A Git repository gives you version history, access control, and a full audit trail for free, because every edit becomes a tracked change with a date and an author. An AI agent can pull the whole repository and start reading the files immediately.
Should Your Business Adopt OKF Now?
There is no urgent rush. OKF is still version 0.1, and it will change as people implement it and best practices emerge. Those best practices will likely get folded back into future versions of the standard.
The spec is also permissive by design. Tools have to accept unknown types and extra fields, so partial or custom setups will not break anything. You can start small with your most important documents and expand from there.
Even with the version 0.1 caveat, adopting it now is safe in my view. It is so close to the best practices that already exist, and it fits so well with where AI is heading, that there is little downside. If you have not started collecting this knowledge yet, start immediately.
How OKF Fits With the Brand Ambassador We Build for Clients
For every client, we build a Brand Ambassador. It is an AI project containing about 12 markdown documents covering the company overview, products and services, brand voice, content guidelines, competitors, and important pages. AI can handle most knowledge work on its own, but it cannot develop a deep understanding of your specific brand without this.
My team is already talking about how we adapt our current Brand Ambassadors to the OKF structure. The overlap is high, since we are already working in organized markdown files with clear descriptions.
The work of getting started is the same work we tell every client to begin with. If you want a head start, you can build an AI knowledge base using the same approach we use, then align it to OKF as the standard settles.
Getting Your Knowledge Base Ready for AI
We build and maintain AI knowledge bases for the businesses we work with, and we are adapting them to OKF as the standard matures. Contact TJ Digital for a free digital marketing audit, and we will show you exactly where to start with your own knowledge base.
Common Questions About Google’s Open Knowledge Format
Is OKF the same as LLMs.txt?
No. They solve different problems. LLMs.txt and WebMCP help AI agents understand and use your public website, while OKF structures your internal company knowledge for your own agents and tools.
Do you need GitHub to use OKF?
No. OKF requires no specific tooling, so any text editor, file system, or search tool can read the files. We recommend GitHub anyway, because Git gives you version control and access management for free.
Is OKF free to use?
Yes. It is an open, vendor-neutral specification. The files are plain markdown with YAML headers, so there is no software to buy and no SDK to install.